
What is the Issue?
If you have any experience with PyTorch training loops you might have noticed it is just annoying to write and also probably way to complicated, especially if you are used to the Sklearn or Keras fit function.
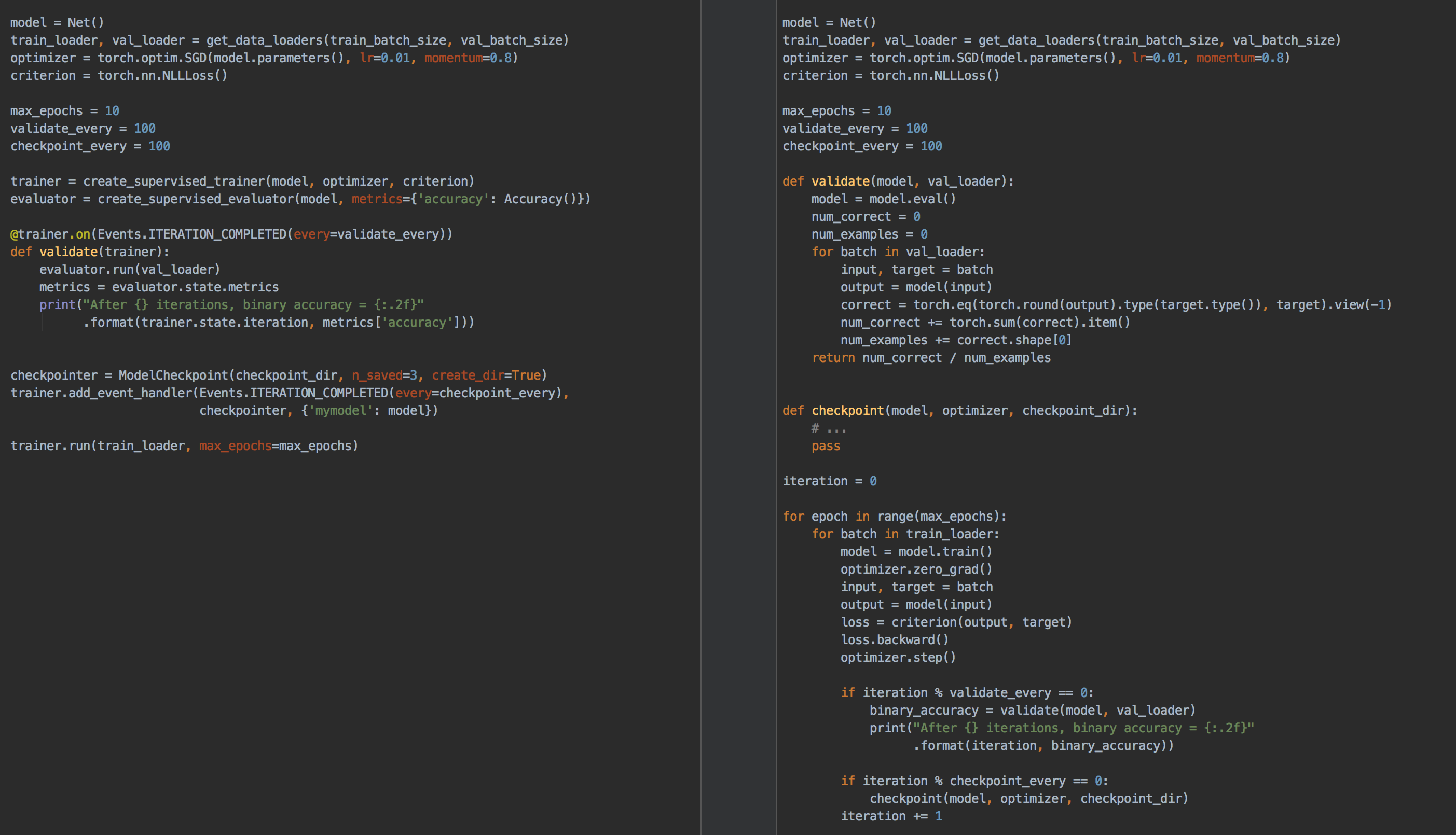
For visualization here is an example of a PyTorch training loop:
for epoch in range(epochs):
running_loss = 0.
for data in train_dataloader:
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print("Epoch {} loss: {}".format(epoch + 1, running_loss / len(train_dataloader)))
In comparison this is what you would do in Keras:
model.compile(optimizer, loss)
model.fit(inputs, labels, batch_size, epochs)
What is Ignite?
Ignite is a high-level library to help with training neural networks in PyTorch.
Ignite Core Elements
Before you can use it, it has to be installed. You can do a pip install
pip install pytorch-ignite
or use an anaconda installation
conda install ignite -c pytorch
Engine
The main aspect of Ignite is the so called engine. The engine defines the training loop and creates events which will be discussed in the next section. The engine class takes as an argument some kind of process function. You can define this function yourselfes and might look like this:
def process_function(engine, batch):
inputs, targets = batch
optimizer = zero_grad()
outputs = model(inputs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
return loss.item()
That is your training loop. Now we just have to run it.
This can be done by calling the run function on the engine.
engine = Engine(process_function)
engine.run(dataloader)
The dataloader should be a PyTorch DataLoader object. You can for example define one for your train and another one for your validation/test set.
If you have a pretty standard supervised learning task, Ignite offers the functions create_supervised_trainer and create_supervised_evaluator. Both of them take as input your
network and optionally some kind of metrics you want to evaluate, the supported device (CPU or GPU) as well as a prepare_batch and a non_blocking argument.
Events
An event occurs during the training process. Events which are being fired by the engine are:
- COMPLETED
- EPOCH_COMPLETED
- EPOCH_STARTED
- EXCEPTION_RAISED
- ITERATION_COMPLETED
- ITERATION_STARTED
- STARTED
You can use those events for example to perform some printing or logging. A practical usecase is to define
Handlers to deal with the given event.
Handlers
Practical Example
After giving insight into the core concepts of the library, I just want to give a short example how it can look like in your project. The following example also utilizes TensorBoardX.
loss = nn.MSELoss()
def create_summary_writer(model, data_loader, log_dir):
writer = SummaryWriter(log_dir=log_dir)
data_loader_iter = iter(data_loader)
x, y = next(data_loader_iter)
x = x.view(x.shape[0], -1)
try:
writer.add_graph(model, x)
except Exception as e:
print("Failed to save model graph: {}".format(e))
return writer
def fit(model, loss, get_dataloader, learning_rate=1e-2, log_interval=10, log_dir="board"):
train_loader, val_loader = get_dataloader
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
writer = create_summary_writer(model, train_loader, log_dir)
optimizer = optim.Adam(model.parameters(), learning_rate)
trainer = create_supervised_trainer(model, optimizer, loss, device=device)
evaluator = create_supervised_evaluator(model, device=device,
metrics={'loss': ignite.metrics.Loss(loss)})
@trainer.on(Events.ITERATION_COMPLETED)
def log_training_loss(engine):
iter = (engine.state.iteration - 1) % len(train_loader) + 1
if iter % log_interval == 0:
writer.add_scalar("training/loss", trainer.state.output, trainer.state.iteration)
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(trainer):
evaluator.run(train_loader)
metrics = evaluator.state.metrics
writer.add_scalar("training/avg_loss", metrics['loss'], trainer.state.epoch)
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(trainer):
evaluator.run(val_loader)
metrics = evaluator.state.metrics
writer.add_scalar("validation/avg_loss", metrics['loss'], trainer.state.epoch)
trainer.run(train_loader, max_epochs=epochs)
writer.close()
